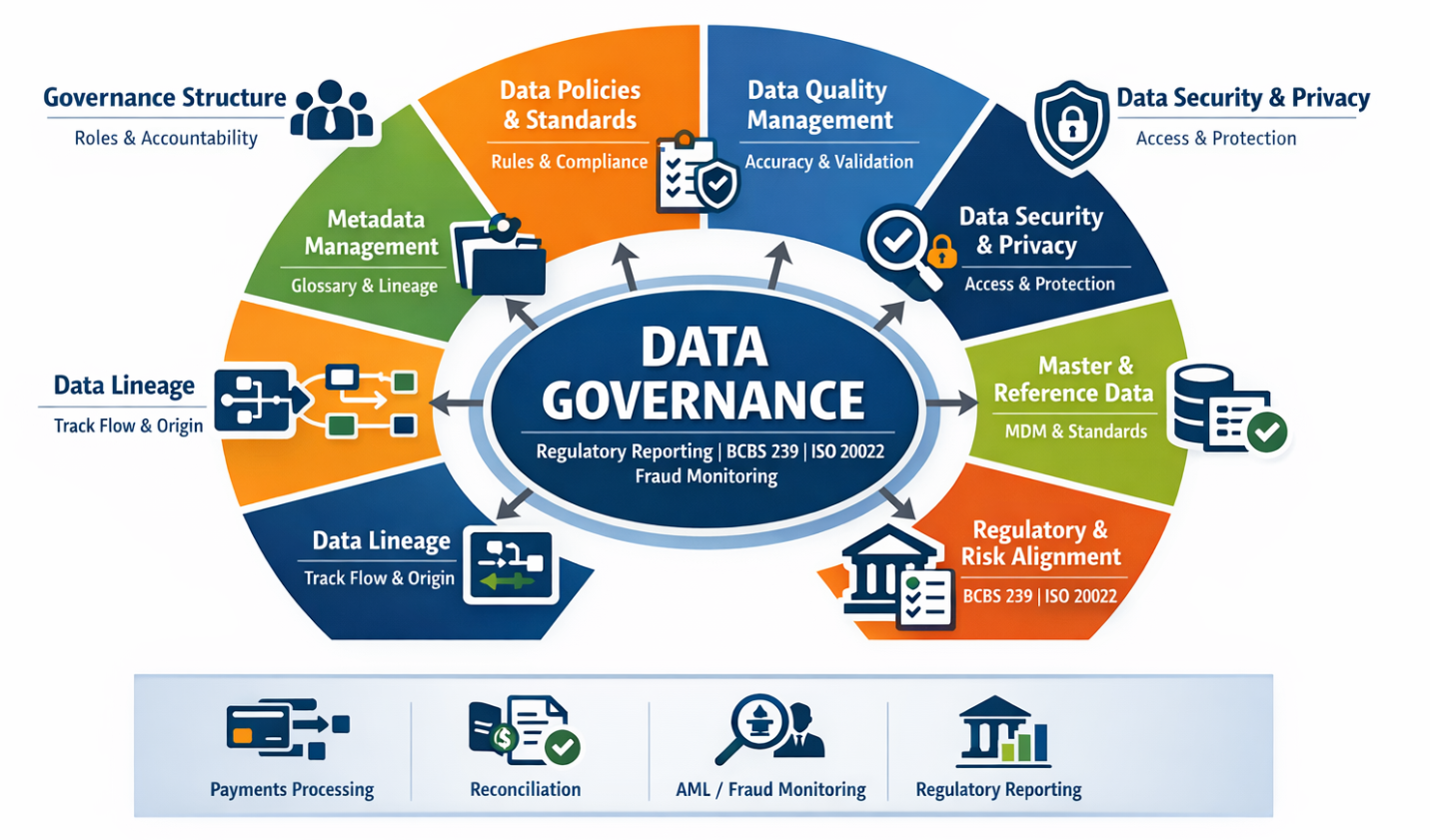
In today’s data-driven world, organizations generate and consume more data than ever before. But having large volumes of data alone does not guarantee better decisions. Without proper structure, ownership, and controls, data can quickly become inaccurate, inconsistent, and risky.
This is where data governance plays a critical role. As FDO / CDO , ensure that data is: Trusted – accurate, complete, and reliable Secure – protected from unauthorized access and misuse Compliant – aligned with regulatory and legal requirements Accessible – available to the right people at the right time For engineers, data governance answers a few non-negotiable questions: – Can I trust this dataset? – Who owns it, and who can touch it? – Where did it come from, and what breaks if I change it? The highest-leverage governance decision isn’t about dashboards, it’s about **stopping bad data early** – a ‘data contract’, not best-effort ingestion. In AWS ingestion, we enforce schemas, use only structured formats (Parquet/Avro), fail pipelines on schema drift, and quarantine invalid records.
Because if bad data lands, governance has already failed. Consistent S3 structure (s3://data/<domain>/<source>/<entity>/year=/m/day=/) enables automated retention, pruning, and safe reprocessing. Without it, every team reinvents the wheel, making governance impossible. The Control Plane for Your Data: Metadata AWS Glue Catalog and Snowflake combine to give us lineage, impact analysis, ownership, and audit readiness.
If metadata isn’t automated, it’s wrong, period. Governance by Design: Layered Data Models Strong platforms enforce data layers: **Raw** (immutable), **Curated** (cleaned), **Analytics** (business-ready). Each layer has distinct access, quality, and retention. This prevents chaos. Our two-layer security approach: IAM for platform access, RBAC for data access. Roles represent personas, and raw data is never directly exposed.
If you grant direct user access, you’ve lost. Privacy with Snowflake’s Classification & Masking Snowflake’s tag-based governance gives us column-level sensitivity, dynamic masking, and role-aware visibility. No hard-coded logic, no duplicated SQL. This is privacy-by-design at scale. Data Quality: Pipeline Invariant, Not a Dashboard Data quality isn’t just a metric; it’s runtime enforcement: null constraints, PK uniqueness, referential integrity.
Checks fail pipelines, emit metrics, trigger alerts, and are version-controlled. Because without lineage, every schema change is a production risk. What’s one step you’re taking today to strengthen your data’s integrity?
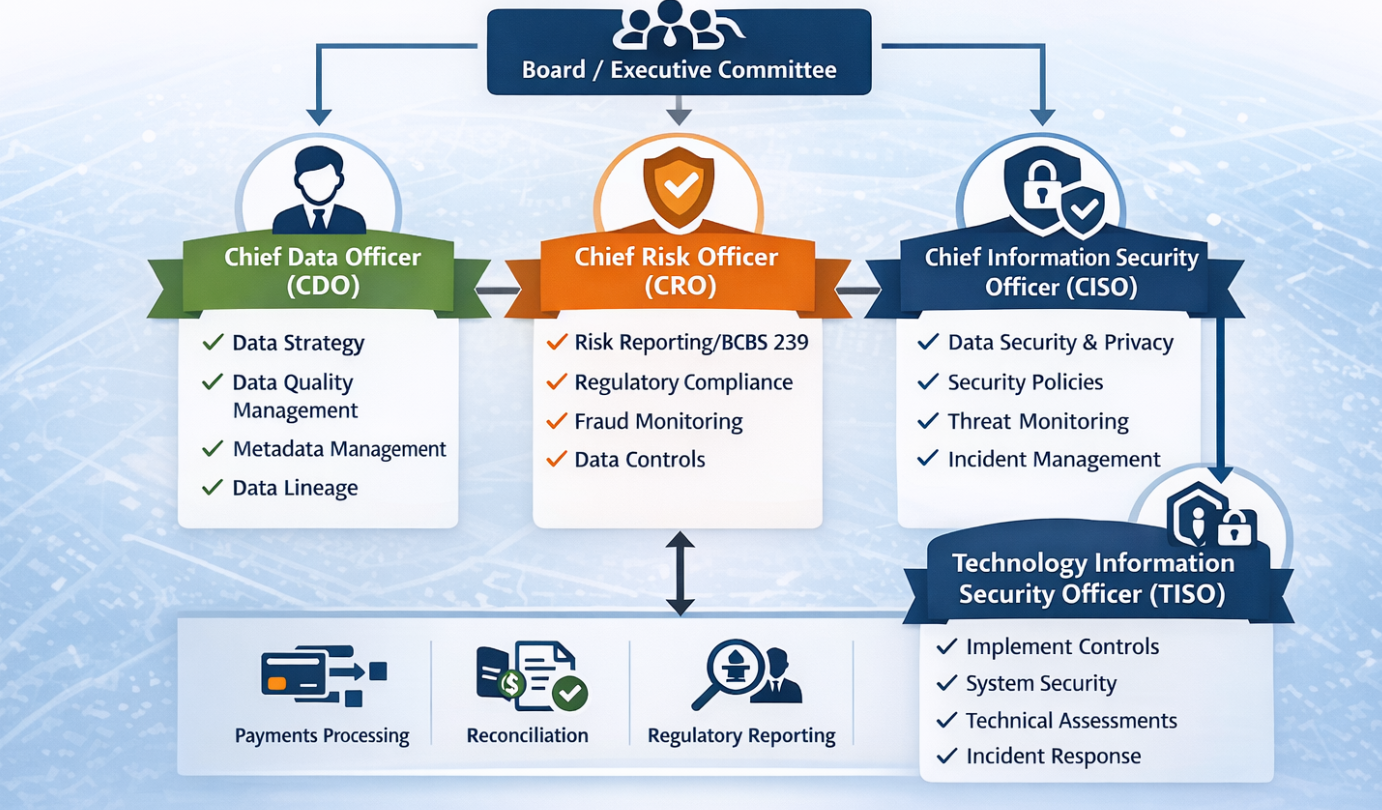
Producer–Consumer Dataset Mismatch: The Silent Data Platform Killer Most data incidents don’t start with bad code. We’ve all been there, frantically debugging systems only to find the core issue was a silent shift upstream. They start with a “mismatch between data producers and data consumers“.
The producer changes: – A column name – A data type – A nullability rule – A semantic meaning Meanwhile, the consumer assumes: – The schema is stable – The data is backward compatible – The numbers still mean the same thing Nothing fails immediately. Pipelines run. Dashboards refresh. Models retrain. But the data is now **quietly wrong**, leading to delayed decisions and eroded trust. This is not a tooling problem. It’s fundamentally a contract problem.
The real fix isn’t just more monitoring — it’s an overhaul in how we think about data ownership: – Explicit data contracts – Schema versioning – Strict backward-compatibility rules – Clear ownership on the producer side – Automated validation at ingestion If producers can change data without breaking something, consumers will eventually trust the wrong numbers. I’ve witnessed the chaos this causes first-hand. Data governance exists to make breaking changes loud.
Good governance breaks pipelines early, preventing costly downstream errors. Bad governance lets bad data flow silently, turning minor issues into major operational blind spots. What’s been your most challenging ‘silent data killer‘ incident, and how did you tackle it?
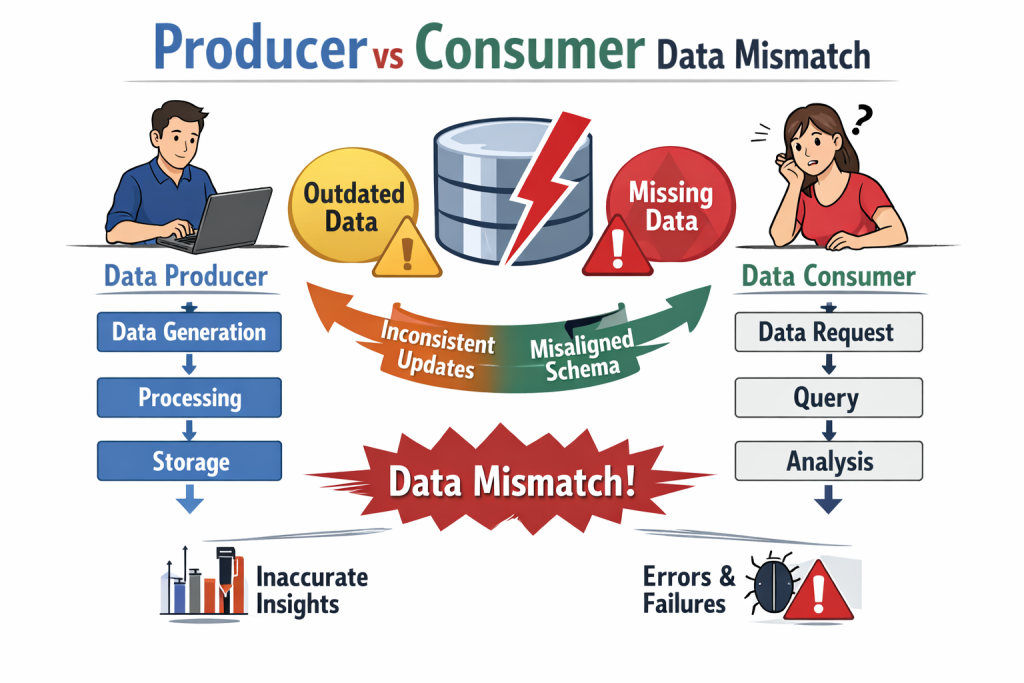
I once saw a silent data defect cost a company $X million over six months because it wasn’t an outage, it was worse: an invisible erosion of correctness. Most data defects don’t cause outages. They cause **silent correctness issues** — and those are worse. Releasing data fixes without governance turns every correction into a new risk. Strong data teams treat data defects like **production incidents**, not ad-hoc patches. Here are **data-governed best practices** for releasing data defect fixes:
Classify the Defect First Not all data defects are equal: – Schema defects (type, nullability, missing columns) – Logic defects (wrong joins, filters, aggregations) – Freshness defects (late or missing data) – Semantic defects (numbers are correct but *mean* the wrong thing) Governance starts by making defect types explicit. Identify Blast Radius via Lineage Before releasing a fix, teams must know: – Which downstream tables are impacted
Which dashboards, reports, or models consume the data * Whether historical data must be corrected No lineage = no safe release. Version, Don’t Overwrite Never silently overwrite consumer-facing data.
Failing to version silently erodes trust and can lead to entire business units making decisions on flawed historical metrics. – Create a new table or view version – Backfill with corrected logic – Deprecate old versions with a clear timeline Breaking changes must be explicit, not implicit. Enforce Validation Gates
Every data defect fix should pass: – Schema validation – Data quality checks (row counts, nulls, keys) – Reconciliation against known benchmarks – Freshness SLAs If validation isn’t automated, the defect isn’t truly fixed. Communicate Like an API Change Data fixes must be communicated: – What changed – Why it changed – What data range is affected – What consumers must do Data governance treats consumers as first-class users, not afterthoughts.
Audit and Record the Fix Governed releases leave an audit trail: – Root cause – Impacted datasets – Fix version – Release date This prevents repeat incidents and supports compliance. Promote via Environments Defect fixes should move through: – Dev → QA → Pre-Prod –> PROD – With the same governance checks at every stage Hot-fixing directly in production is a governance failure.
Data defects are inevitable. Ungoverned data releases are optional. Strong data governance doesn’t prevent defects — it prevents *silent damage*. Mastering governed releases isn’t just about preventing damage, it’s about elevating your data team’s reliability and reputation. What’s the riskiest ungoverned release you’ve witnessed, and what was the true cost?